4. Heaps / Priority Queues
Table of Contents
A. General Introduction
Heaps are concrete data structures, whereas priority queues are abstract data structures. An abstract data structure determines the interface, while a concrete data structure defines the implementation.1
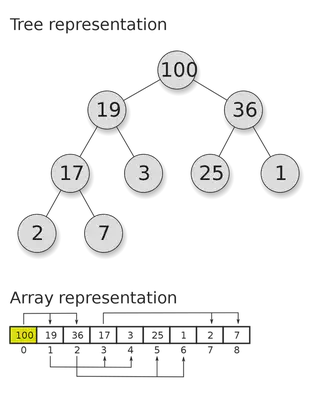
In a heap tree, the value in a node is always smaller than both of its children. This is called the heap property.
Generally, heaps can be of two types
- Min-heap: The smallest element is always at the root of the tree.
- Max-heap: The largest element is always at the root of the tree.
Time Complexity
| Operation | Worst-case Time complexity |
|---|---|
| Build a binary heap (heapify) | O(n) |
| Insert an element | O(log n) |
| Delete an element | O(log n) |
| Find the max/min | O(1) |
| Find the kth largest element (max-heap) | O(k*log(n)) |
| Heap sort | O(n*log(n)) |
B. Leetcode Problems
1046. Last Stone Weight
You are given an array of integers stones where stones[i] is the weight of the ith stone.
We are playing a game with the stones. On each turn, we choose the heaviest two stones and smash them together. Suppose the heaviest two stones have weights x and y with x <= y. The result of this smash is:
If x == y, both stones are destroyed, and
If x != y, the stone of weight x is destroyed, and the stone of weight y has new weight y - x.
At the end of the game, there is at most one stone left.
Return the weight of the last remaining stone. If there are no stones left, return 0.
Example:
Input: stones = [2,7,4,1,8,1]
Output: 1
Explanation:
We combine 7 and 8 to get 1 so the array converts to [2,4,1,1,1],
we combine 2 and 4 to get 2 so the array converts to [2,1,1,1],
we combine 2 and 1 to get 1 so the array converts to [1,1,1],
we combine 1 and 1 to get 0 so the array converts to [1] then that’s the value of the last stone.
Key Ideas:
- the default implementation in
heapqis min-heap- so the values are made negative to make them max-heap
- When pushing and popping to the heap, the value is negated
Code
import heapq
class Solution:
def lastStoneWeight(self, stones: List[int]) -> int:
stones = [-1*stone for stone in stones]
heapq.heapify(stones)
while len(stones) > 1:
s1 = -1 * heapq.heappop(stones)
s2 = -1 * heapq.heappop(stones) # s2 <= s1
if s1 != s2:
new_stone = -1*(s1 - s2)
heapq.heappush(stones, new_stone)
stones.append(0)
return abs(stones[0])
Time Complexity: O(nlog(n))
703. Kth Largest Element in a Stream
Design a class to find the kth largest element in a stream. Note that it is the kth largest element in the sorted order, not the kth distinct element.
Implement KthLargest class:
KthLargest(int k, int[] nums)Initializes the object with the integerkand the stream of integersnums.int add(int val)Appends the integer val to the stream and returns the element representing thekthlargest element in the stream.
Example:
Input:
[“KthLargest”, “add”, “add”, “add”, “add”, “add”]
[[3, [4, 5, 8, 2]], [3], [5], [10], [9], [4]]
Output:
[null, 4, 5, 5, 8, 8]
Explanation:
KthLargest kthLargest = new KthLargest(3, [4, 5, 8, 2]);
kthLargest.add(3); // return 4
kthLargest.add(5); // return 5
kthLargest.add(10); // return 5
kthLargest.add(9); // return 8
kthLargest.add(4); // return 8
Key Ideas:
- Always maintain the list size of
k- use heappop to pop the smallest
(n-k)elements
- use heappop to pop the smallest
- when inserting, pop the last element if the size is greater than
k
Code
import heapq
class KthLargest:
def __init__(self, k: int, nums: List[int]):
self.nums = nums
self.k = k
heapq.heapify(self.nums) # O(n)
while len(self.nums) > self.k:
heapq.heappop(self.nums)
def add(self, val: int) -> int:
heapq.heappush(self.nums, val)
if len(self.nums) > self.k:
heapq.heappop(self.nums)
return self.nums[0] # using a min-heap
Time complexity:
- The constructor’s time complexity would be
O(nlog(n) + (n-k)log(n))->O(nlog(n)) - The add’s time complexity would be
O(log(n)), as the heap is always maintained at sizek
973. K Closest Points to Origin
Given an array of points where points[i] = [xi, yi] represents a point on the X-Y plane and an integer k, return the k closest points to the origin (0, 0).
The distance between two points on the X-Y plane is the Euclidean distance (i.e., √(x1 - x2)^2 + (y1 - y2)^2).
You may return the answer in any order. The answer is guaranteed to be unique (except for the order that it is in).
Example:

Input: points = [[1,3],[-2,2]], k = 1
Output: [[-2,2]]
Explanation:
The distance between (1, 3) and the origin is sqrt(10).
The distance between (-2, 2) and the origin is sqrt(8).
Since the distance between (-2, 2) and the origin is less than the distance between (1, 3) and the origin, (-2, 2) is closer to the origin.
Key Ideas
- compute the distance of each point to the origin and store it in a list
- To get the k-nearest points, I tried two different methods and both seem to work
- Method 1: Heaps
- Use a min-heap to store the k-nearest points
- pop
kelements from the heap and return the points
- Method 2: Sort
- Sort the list of distances and return the first
kelements
- Sort the list of distances and return the first
- Method 1: Heaps
Code - Heap method
import heapq
class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
# 1. Compute the euclidean distance from the origin
# 2. heap push all points -> nlogn
# 3. pop `k` elements from the heap -> klogn
distances = []
compute_distance = lambda x,y: (x**2 + y**2)**(0.5)
for x,y in points:
dist = compute_distance(x,y)
heapq.heappush((dist, [x,y]))
k_nearest = []
for _ in range(k):
_, pt = heapq.heappop(distances)
k_nearest.append(pt)
return k_nearest
Time complexity: O((n+k)log(n))
Code - Sort method
import heapq
class Solution:
def kClosest(self, points: List[List[int]], k: int) -> List[List[int]]:
distances = []
compute_distance = lambda x,y: (x**2 + y**2)**(0.5)
for x,y in points:
dist = compute_distance(x,y)
distances.append((dist, [x, y]))
distances = sorted(distances, key=lambda x: x[0]) # nlogn
k_nearest = []
for i in range(k): # k
_, pt = distances[i]
k_nearest.append(pt)
return k_nearest
Time complexity: O(nlog(n))
355. Design Twitter
Design a simplified version of Twitter where users can post tweets, follow/unfollow another user, and is able to see the 10 most recent tweets in the user’s news feed.
Implement the Twitter class:
Twitter()Initializes your twitter object.void postTweet(int userId, int tweetId)Composes a new tweet with IDtweetIdby the user userId. Each call to this function will be made with a uniquetweetId.List<Integer> getNewsFeed(int userId)Retrieves the 10 most recent tweet IDs in the user’s news feed. Each item in the news feed must be posted by users who the user followed or by the user themself. Tweets must be ordered from most recent to least recent.void follow(int followerId, int followeeId)The user with IDfollowerIdstarted following the user with IDfolloweeId.void unfollow(int followerId, int followeeId)The user with IDfollowerIdstarted unfollowing the user with IDfolloweeId.
Example:
Input > [“Twitter”, “postTweet”, “getNewsFeed”, “follow”, “postTweet”, “getNewsFeed”, “unfollow”, “getNewsFeed”]
[[], [1, 5], [1], [1, 2], [2, 6], [1], [1, 2], [1]]
Output [null, null, [5], null, null, [6, 5], null, [5]]
Explanation
Twitter twitter = new Twitter();
twitter.postTweet(1, 5);
// User 1 posts a new tweet (id = 5). twitter.getNewsFeed(1); // User 1’s news feed should return a list with 1 tweet id -> [5]. return [5]
twitter.follow(1, 2); // User 1 follows user 2.
twitter.postTweet(2, 6); // User 2 posts a new tweet (id = 6).
twitter.getNewsFeed(1); // User 1’s news feed should return a list with 2 tweet ids -> [6, 5]. Tweet id 6 should precede tweet id 5 because it is posted after tweet id 5.
twitter.unfollow(1, 2); // User 1 unfollows user 2.
twitter.getNewsFeed(1); // User 1’s news feed should return a list with 1 tweet id -> [5], since user 1 is no longer following user 2.
Key Ideas:
The tricky part of the problem was the use of multiple data structures for the problem.
- Use a
hashmapto store the tweets tweeted by each userId - Use a
hashmapto store the users who are following each userId - when a userId posts a tweet, add the tweet as a
tupleto the hashmap with anegative priority value. - To generate a feed, collate all the tweets from the users who are following the userId
- Build a heap from the list of tweets; which takes
O(n) - Pop the top
10elements from the heap and return the list of tweet ids; which takesO(10*logn)$\approx$O(logn)
- Build a heap from the list of tweets; which takes
Code
import heapq
from collections import defaultdict
class Twitter:
def __init__(self):
self.usersConn = defaultdict(list)
self.usersTweets = defaultdict(list)
self.tweet_pr = 0
def postTweet(self, userId: int, tweetId: int) -> None:
self.tweet_pr -= 1
self.usersTweets[userId].append((self.tweet_pr, tweetId))
def getNewsFeed(self, userId: int) -> List[int]:
if userId not in self.usersTweets and userId not in self.usersConn:
return []
feed = []
tweets = self.usersTweets[userId].copy()
for friend in self.usersConn[userId]:
tweets.extend(self.usersTweets[friend])
heapq.heapify(tweets)
while len(feed) < 10 and tweets:
obj = heapq.heappop(tweets)
_, tweetId = obj
feed.append(tweetId)
return feed
def follow(self, followerId: int, followeeId: int) -> None:
if followeeId not in self.usersConn[followerId]:
self.usersConn[followerId].append(followeeId) # O(1)
def unfollow(self, followerId: int, followeeId: int) -> None:
if followeeId in self.usersConn[followerId]:
self.usersConn[followerId].remove(followeeId) # O(n)
621. Task Scheduler
Given a characters array tasks, representing the tasks a CPU needs to do, where each letter represents a different task. Tasks could be done in any order. Each task is done in one unit of time. For each unit of time, the CPU could complete either one task or just be idle.
However, there is a non-negative integer n that represents the cooldown period between two same tasks (the same letter in the array), that is that there must be at least n units of time between any two same tasks.
Return the least number of units of times that the CPU will take to finish all the given tasks.
Example:
Input: tasks = [“A”,“A”,“A”,“B”,“B”,“B”], n = 2
Output: 8
Explanation:
A -> B -> idle -> A -> B -> idle -> A -> B
There is at least 2 units of time between any two same tasks.
Key Ideas:
- use a max-heap to store the tasks’s counter
- have a while loop to simulate time
- pop from the heap, and reduce the counter
- add to the queue with the time at which it can be popped, with the counter
- pop from the heap, and reduce the counter
- if the first element in the queue’s time is same as current time
- pop the element and add it to the heap if the counter is non-zero positive
- update the time
Code
from collections import deque, Counter
import heapq
class Solution:
def leastInterval(self, tasks: List[str], n: int) -> int:
time = 0
queue = deque([])
max_heap = [-v for _, v in Counter(tasks).items()]
heapq.heapify(max_heap)
while queue or max_heap:
if max_heap:
val = heapq.heappop(max_heap)
val += 1
if val < 0:
queue.append((time+n, val))
if queue and queue[0][0] == time:
_, val = queue.popleft()
heapq.heappush(max_heap, val)
time += 1
return time
295. Find Median from Data Stream
The median is the middle value in an ordered integer list. If the size of the list is even, there is no middle value and the median is the mean of the two middle values.
- For example, for
arr = [2,3,4], the median is3. - For example, for
arr = [2,3], the median is(2 + 3) / 2 = 2.5.
Implement the MedianFinder class:
MedianFinder()initializes the MedianFinder object.void addNum(int num)adds the integer num from the data stream to the data structure.double findMedian()returns the median of all elements so far. Answers within10^-5of the actual answer will be accepted.
Example:
Input:
[“MedianFinder”, “addNum”, “addNum”, “findMedian”, “addNum”, “findMedian”]
[[], [1], [2], [], [3], []]
Output:
[null, null, null, 1.5, null, 2.0]
Explanation
MedianFinder medianFinder = new MedianFinder();
medianFinder.addNum(1); // arr = [1]
medianFinder.addNum(2); // arr = [1, 2]
medianFinder.findMedian(); // return 1.5 (i.e., (1 + 2) / 2)
medianFinder.addNum(3); // arr[1, 2, 3]
medianFinder.findMedian(); // return 2.0
Method 1:
Key Ideas:
- use an array to store the stream of numbers
- appending to the array is
O(1) - To find the median, sort the array and compute the median index based on the length of the array;
O(nlogn)
Code
import heapq
class MedianFinder:
def __init__(self):
self.data_stream = []
def addNum(self, num: int) -> None:
self.data_stream.append(num) # O(1)
def findMedian(self) -> float:
m = len(self.data_stream)
self.data_stream.sort() # O(nlogn)
idx = m//2
if m % 2 != 0:
median = self.data_stream[idx]
else:
median = (self.data_stream[idx] + self.data_stream[idx-1])/2
return median
Method 2:
Key Ideas:
- Maintain two heaps to store the lower and upper halves of the stream of numbers
- The lower half consists of small numbers of data stream; max-heap
- The upper half consists of large numbers of data stream; min-heap
- By using two heaps, we have a slight tradeoff in the time complexity of
addNumtoO(logn)instead ofO(1)- By default, we always add a new number to the small number heap
- After adding the number to the small heap, we can check for certain properties to see if we need to balance the heaps
- Property 1: Difference between the sizes of the two heaps should be at most
1- If it is not satisfied, then pop and push the number to the other heap
- Property 2: The root of the min-heap should be larger than the root of the max-heap
- If it is not satisfied
- pop the root of the max-heap and push it to the min-heap
- pop the root of the min-heap and push it to the max-heap
- If it is not satisfied
- Property 1: Difference between the sizes of the two heaps should be at most
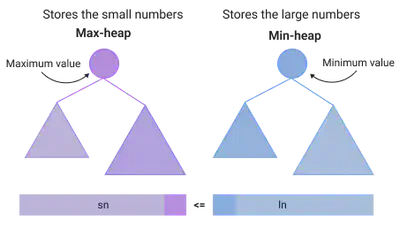
findMedian()
- As we have two heaps to store the stream of numbers, the time complexity of
findMedianisO(1)- Why? Because we know that the median can be computed from the roots of two heaps, as atmost one heap will have one more element than the other.
Code
import heapq
class MedianFinder:
def __init__(self):
self.sn = [] # heap for small numbers
self.ln = [] # heap for large numbers
def addNum(self, num: int) -> None:
# 1. Add it to sn and check if all the properties are satisfied
# Prop 1: Difference in the sn and ln should at most 1
# Prop 2: Max value in the sn should be less than min value in the ln
heapq.heappush(self.sn, -num)
if len(self.sn) > 1 + len(self.ln):
val = -1*heapq.heappop(self.sn)
heapq.heappush(self.ln, val)
if len(self.ln) > 1 + len(self.sn):
val = heapq.heappop(self.ln)
heapq.heappush(self.sn, -val)
if self.sn and self.ln and self.sn[0] < self.ln[0]:
val = -1*heapq.heappop(self.sn)
heapq.heappush(self.ln, val)
val = heapq.heappop(self.ln)
heapq.heappush(self.sn, -val)
def findMedian(self) -> float:
if len(self.sn) > len(self.ln):
# there are odd number of elements
return -1 * self.sn[0]
elif len(self.ln) > len(self.sn):
return self.ln[0]
v1 = self.ln[0]
v2 = -1*self.sn[0]
return (v1+v2)/2